MLOps Kya Hai? Jab ML Model Notebook Se Bahar Niklata Hai!
Maan lo tumne ek amazing ML model banaya — 95% accuracy, perfect predictions. Tum excited ho, team excited hai. Par phir ek problem aata hai—"Yaar, is model ko actual app mein kaise daalenge? Kal phir train karna padega? Agar model kharab result dene lage toh kaise pata chalega?"
Yahan aata hai MLOps!
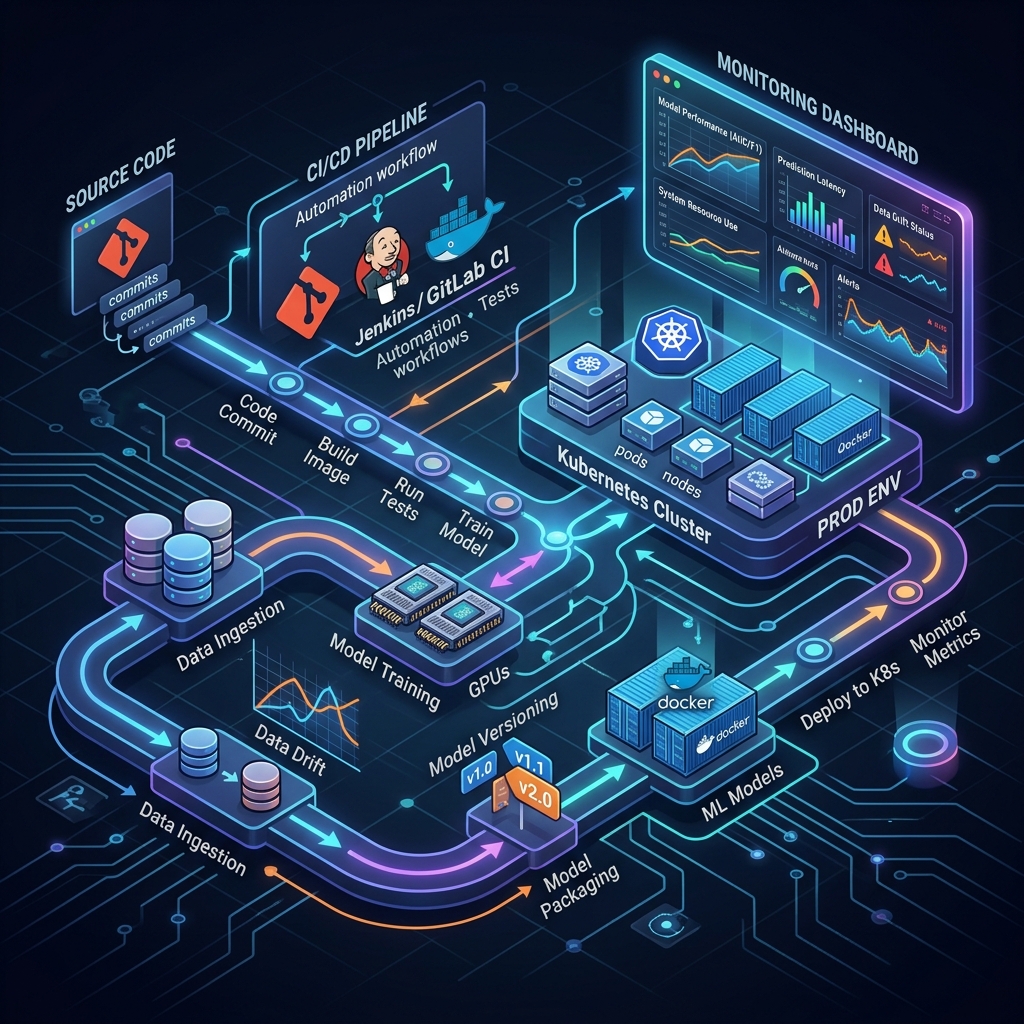
MLOps Kya Hai?
MLOps (Machine Learning Operations) ek set of practices, tools, aur processes hai jo ML models ko reliably aur efficiently design karne, develop karne, aur production mein deploy aur maintain karne ke liye use hoti hain.
Isko simple karo: DevOps + Machine Learning = MLOps.
Jaise developers ke liye DevOps hai (CI/CD, testing, deployment), waise hi ML engineers ke liye MLOps hai.
Bina MLOps ke Kya Hota Hai?
Ek typical "notebook ML" workflow:
- Data download karo manually
- Model train karo local machine par
- Results screenshot lo
- Model email/drive par share karo
- Koi aur manually deploy kare
- 3 months baad model stale ho jaaye—kisi ko pata nahi
Problems:
- Reproducibility zero (koi nahi jaanta model kaise bana)
- Monitoring nahi (pata nahi model kab behave karna band kar de)
- Collaboration mushkil (code, data, experiments scattered)
- Deployment manual aur error-prone
MLOps ka Full Lifecycle
Data → Preprocessing → Training → Evaluation → Deployment → Monitoring → Retraining
↑_______________________________________________________|
(Continuous Loop)
1. Data Management
Data Versioning: Code ki tarah data bhi version control mein hona chahiye.
# DVC (Data Version Control) — Git for Data
pip install dvc
dvc init
dvc add data/training_data.csv # Data track karo
git add data/training_data.csv.dvc
git commit -m "Add training dataset v1"
# S3/GCS par store karo
dvc push
2. Experiment Tracking
Har training run ka record rakho — kaunse hyperparameters, kaunsa accuracy.
import mlflow
with mlflow.start_run():
# Parameters log karo
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("epochs", 100)
# Train karo
model.fit(X_train, y_train)
# Metrics log karo
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)
# Model save karo
mlflow.sklearn.log_model(model, "model")
MLflow UI mein sab experiments compare kar sakte hain — bilkul spreadsheet ki tarah.
3. Model Registry
Trained models ko centrally manage karo:
# Model register karo
mlflow.register_model("runs:/run_id/model", "MyClassifier")
# Production mein promote karo
client = mlflow.tracking.MlflowClient()
client.transition_model_version_stage(
name="MyClassifier",
version=3,
stage="Production"
)
4. CI/CD for ML
Har code change par automatically test aur deploy:
# .github/workflows/ml-pipeline.yml
name: ML Pipeline
on:
push:
branches: [main]
jobs:
train-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run tests
run: pytest tests/
- name: Train model
run: python train.py
- name: Evaluate model
run: python evaluate.py
- name: Deploy if accuracy > threshold
run: python deploy.py
5. Model Serving
Model ko API ke through serve karna:
# FastAPI se simple model server
from fastapi import FastAPI
import joblib
import numpy as np
app = FastAPI()
model = joblib.load("model.pkl")
@app.post("/predict")
def predict(features: list):
prediction = model.predict([features])
return {"prediction": prediction[0]}
uvicorn main:app --host 0.0.0.0 --port 8000
6. Model Monitoring
Production mein model ko observe karte rehna:
Kya monitor karein:
- Data Drift: Input data ka distribution badal gaya?
- Concept Drift: Real-world patterns change ho gaye?
- Model Performance: Accuracy drop ho rahi hai?
- Latency: Response time slow ho raha hai?
from evidently import ColumnMapping
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
# Data drift detect karo
report = Report(metrics=[DataDriftPreset()])
report.run(reference_data=train_df, current_data=production_df)
report.save_html("drift_report.html")
MLOps Tools Ecosystem
| Category | Tools |
|---|---|
| Experiment Tracking | MLflow, Weights & Biases, Comet ML |
| Data Versioning | DVC, LakeFS, Delta Lake |
| Pipeline Orchestration | Airflow, Kubeflow, Prefect |
| Model Serving | BentoML, Seldon Core, TorchServe |
| Monitoring | Evidently, Grafana, Prometheus |
| Feature Store | Feast, Tecton, Vertex Feature Store |
| Container | Docker, Kubernetes |
MLOps Maturity Levels
Companies MLOps ko stages mein adopt karti hain:
Level 0 — Manual:
- Sab kuch manual, notebooks par
- No automation, no monitoring
- (Most startups here)
Level 1 — ML Pipeline Automation:
- Automated training pipeline
- Data validation
- Basic experiment tracking
Level 2 — CI/CD Pipeline:
- Automated testing of models
- Continuous deployment
- Production monitoring
- (Google, Netflix, Uber level)
MLOps vs DevOps — Kya Farq Hai?
| Aspect | DevOps | MLOps |
|---|---|---|
| Versioning | Code | Code + Data + Model |
| Testing | Unit/Integration tests | Data validation + Model evaluation |
| Deployment | Once | Retrain + redeploy continuously |
| Monitoring | Server metrics | Data drift + model performance |
FAQs
1. Kya junior ML engineer ko MLOps aana chahiye? Basic MLOps (MLflow, DVC) zaroor seekhna chahiye. Advanced tools (Kubernetes, Kubeflow) experience ke saath aate hain.
2. MLOps seekhne ke liye kahan se start karein? MLflow se start karo — install karna aur use karna simple hai. Phir DVC, phir Docker.
3. Kya bina cloud ke MLOps kar sakte hain? Haan! MLflow aur DVC locally bhi run karte hain. Cloud integrate karna optional (par preferred) hai.
4. MLOps Engineer ki salary kitni hoti hai India mein? 2026 mein 12-35 LPA range mein hai depending on experience aur company.
5. MLOps aur Data Engineering mein kya farq hai? Data Engineering data pipelines banata hai. MLOps ML-specific pipelines banata hai (training, evaluation, deployment). Dono overlap karte hain.
Aapke project mein MLOps implement karna chahoge? Kahan se shuruat karenge? Comment karein! ⚙️