Aapne GPT-3, GPT-4, aur ab GPT-4o ke baare mein suna hoga. Ye "GPT" shabd ka asli matlab kya hai aur iske piche ka engine kaise chalta hai? Ise samajhna thoda complex lag sakta hai, par is guide mein hum ise bilkul simple "Pizza Shop" analogy se samjhenge.
1. The GPT Breakdown
GPT teen bade words se bana hai:
- Generative: Ye naya content (Text) paida karta hai.
- Pre-trained: Ise pehle se internet ke arbon words padhaye gaye hain.
- Transformer: Ye wo "Architecture" hai jo words ke beech ka rishta samajhta hai.
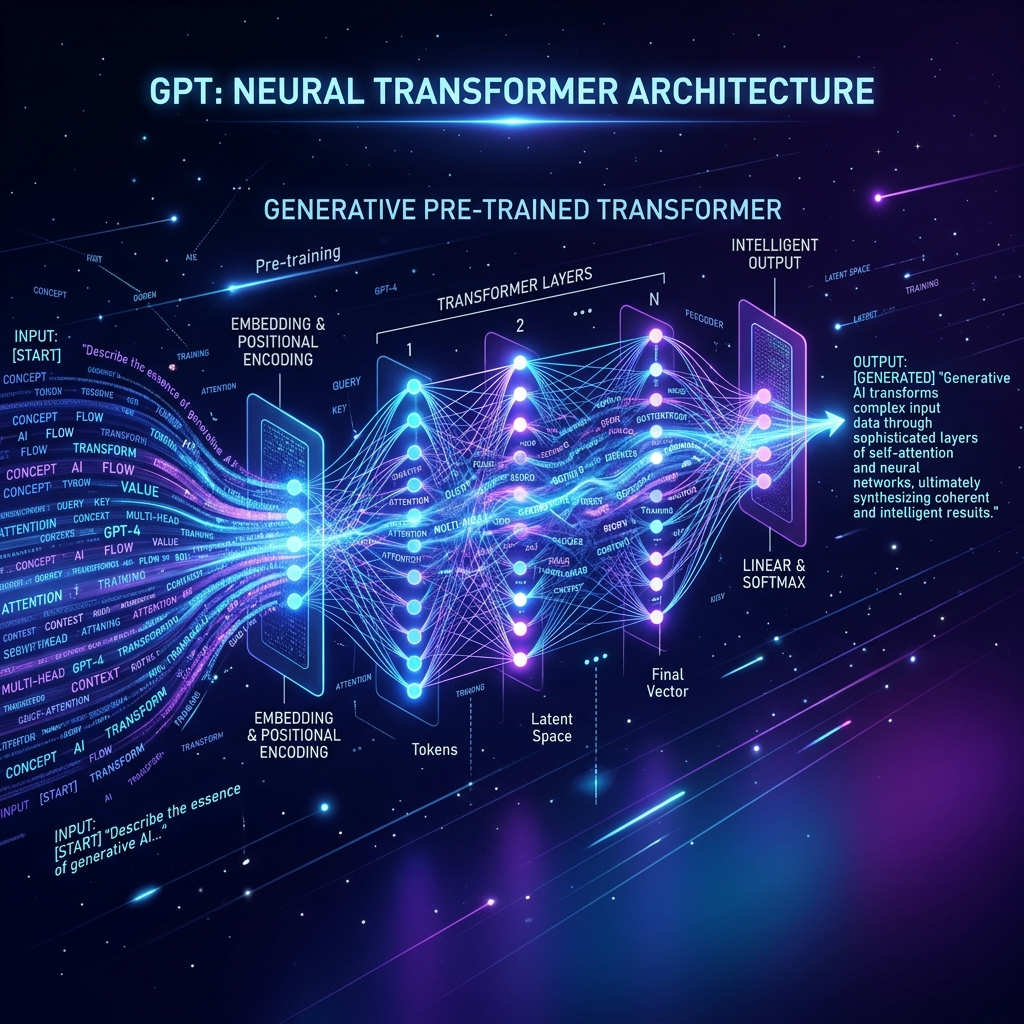
2. Transformer & Self-Attention: The Magic
Pehle ke models (RNN/LSTM) words ko line-by-line padhte the, jis se wo shuruat ka context bhul jate the.
- Self-Attention: Transformer ek saath poore sentence ko "Dekhta" hai.
- Wo har word ko ek "Importance Score" deta hai.
- Example: "Bank" shabd ka matlab "Nadi ka kinara" hai ya "Paise rakhne ki jagah", ye Transformer aas-paas ke words se "Attention" dekar samajh jata hai.
3. Auto-regressive: The Guessing Game
GPT hamesha "Next Word Prediction" karta hai.
- Ye pehle word se shuru karta hai, phir doosra guess karta hai, phir pehle do ko dekh kar teesra guess karta hai.
- Ise Auto-regressive kehte hain.
- Ye process itni fast hoti hai ki humein lagta hai ki AI poora paragraph ek saath soch raha hai.
4. Pre-training vs Fine-tuning
GPT ka banana do stages mein hota hai:
- Pre-training (General Knowledge): Model internet ki saari books aur articles padhta hai. Ise duniya ki basic samajh aa jati hai.
- Fine-tuning (Specialized Knowledge): Model ko specific kaam sikhaya jata hai (jaise Coding ya Customer Support). Ise hum "Supervised Learning" bhi kehte hain.
5. Summary Table: GPT Engine Logic
| Component | Function | Analogy |
|---|---|---|
| Tokenizer | Words ko numbers mein todna | Ingredients taiyar karna |
| Embedding | Words ka matlab vector mein | Taste profile banana |
| Attention | Context samajhna | Sahi toppings chunna |
| Softmax | Final word select karna | Pizza deliver karna |
FAQs
1. GPT aur BERT mein kya fark hai? BERT dono taraf (Aage-Piche) padhta hai, isliye wo "Understanding" mein accha hai. GPT sirf aage predict karta hai (Auto-regressive), isliye wo "Generating" mein champion hai.
2. GPT "Hallucinate" kyon karta hai? Kyonki wo sirf "Next Word" guess kar raha hai. Use ye nahi pata ki jo wo bol raha hai wo factually correct hai ya nahi. Uske liye sirf "Probability" matter karti hai.
3. "Transformer" architecture kisne banaya? Google ke researchers ne 2017 mein ek paper publish kiya tha — "Attention is All You Need". Wahi se GPT ki shuruat hui.
4. 2026 mein GPT se aage kya hai? Ab hum State Space Models (SSM) par research kar rahe hain jo Transformers se bhi zyada fast aur efficient ho sakte hain long documents ke liye.
GPT sirf ek chatbot nahi, balki "Mathematics of Language" ka sabse bada chamatkar hai! ⚡
Tarun ke baare mein: Tarun transformer dynamics aur attention-based cognitive modeling ke specialist hain. AI-Gyani par har prediction logical hai.