AI Development Workflow: Ek Idea Ko Real AI Product Mein Kaise Badlen?
Bahut saare log AI seekh lete hain—algorithms samjhte hain, code likhna jaante hain—par jab khud ka project banane ki baari aati hai, toh confuse ho jaate hain. "Kahan se shuru karoon? Kya steps follow karoon?"
Aaj main aapko woh exact workflow sikhaunga jo real-world AI projects mein follow hota hai—beginner se liye production deployment tak!
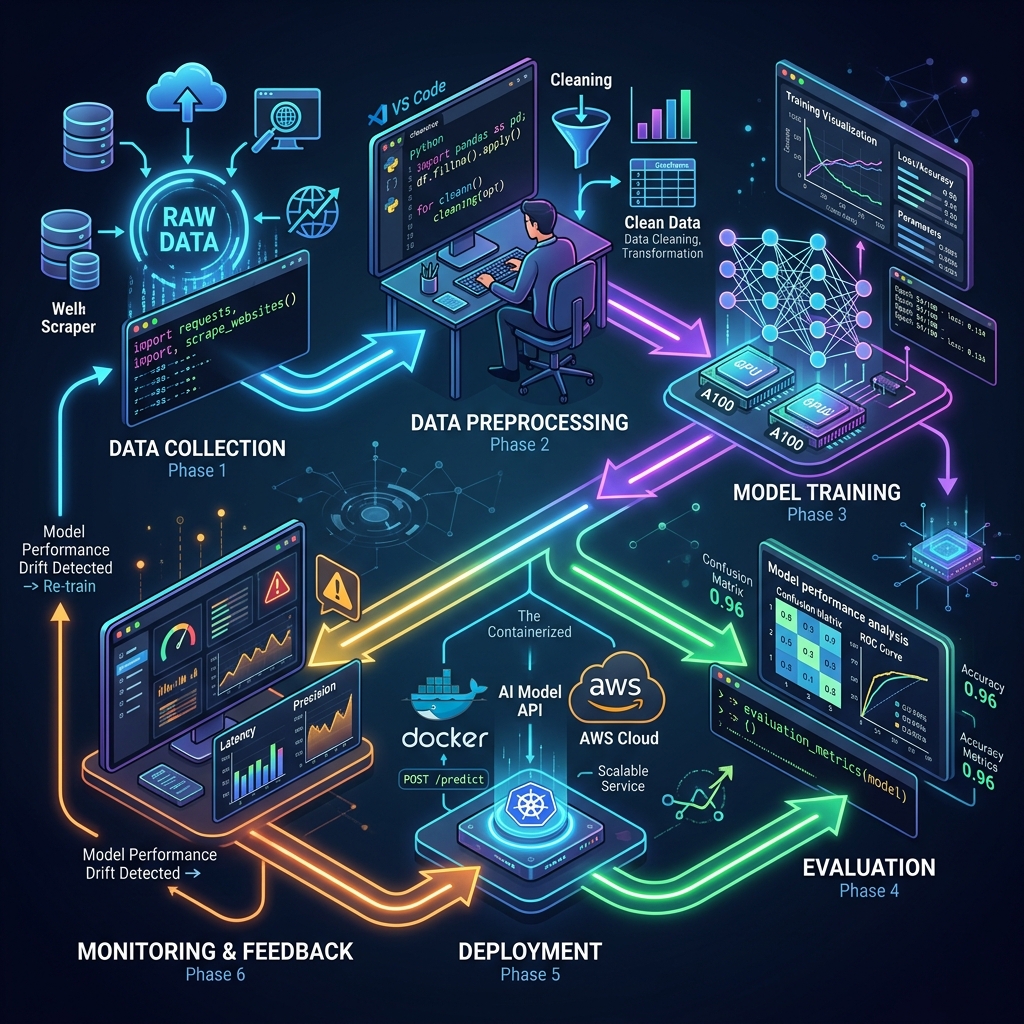
AI Project ke 8 Stages
1. Problem Definition
↓
2. Data Collection
↓
3. Exploratory Data Analysis (EDA)
↓
4. Data Preprocessing
↓
5. Model Selection & Training
↓
6. Model Evaluation
↓
7. Deployment
↓
8. Monitoring & Improvement
Isko "CRISP-DM" ya simple terms mein "AI Lifecycle" bhi kehte hain. Let's go through each stage!
Stage 1: Problem Definition 🎯
Sabse zaroori stage! Zyada log yahan rush karte hain aur baad mein pachtate hain.
Sawaal jo zaroor poochhe:
- Kya solve karna hai? "Customer churn predict karna hai" — specific hona chahiye
- Success kaise measure karein? "80% accuracy", "10% churn reduction"
- ML ki zaroorat hai? Kabhi kabhi simple rules bhi kaam karte hain!
- Data available hai? "Jab data nahi hai, AI nahi hai"
- Timeline kya hai? "3 months mein MVP"
Example:
- ❌ Vague: "AI se business improve karna hai"
- ✅ Specific: "Last 30 days ki website behavior se predict karo ki kaunsa user next 7 days mein churn karega (Yes/No)"
Stage 2: Data Collection 📊
"Data is the new oil" — bilkul sahi baat hai.
Sources:
# Option 1: Existing Database se
import pandas as pd
df = pd.read_sql("SELECT * FROM users WHERE date > '2025-01-01'", conn)
# Option 2: CSV/Excel files
df = pd.read_csv("customer_data.csv")
# Option 3: Web API se
import requests
response = requests.get("https://api.example.com/data",
headers={"Authorization": "Bearer TOKEN"})
df = pd.DataFrame(response.json())
# Option 4: Web Scraping
from bs4 import BeautifulSoup
# (robots.txt check karo pehle!)
Data Collection Checklist:
- Enough data hai? (Rule of thumb: 10x features se zyada samples)
- Labels/targets available hain? (Supervised learning ke liye)
- Data bias toh nahi? (Sab women hain, koi men nahi?)
- Data legal hai use karna? (Privacy compliance)
Stage 3: Exploratory Data Analysis (EDA) 🔍
Data samajhne ka waqt—jaldi mat karo!
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("data.csv")
# Basic overview
print(df.shape) # (rows, columns)
print(df.dtypes) # Data types
print(df.isnull().sum()) # Missing values
print(df.describe()) # Statistics
# Distribution dekho
df['age'].hist(bins=30)
plt.title("Age Distribution")
plt.show()
# Correlation heatmap
sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
plt.show()
# Target variable balance check karo
print(df['churn'].value_counts(normalize=True))
EDA mein kya dhundhe:
- Missing values — kitne hain?
- Outliers — extreme values kahin hain?
- Distribution — normal hai ya skewed?
- Correlations — features ek doosre se related hain?
- Class imbalance — "Yes" aur "No" labels ka ratio?
Stage 4: Data Preprocessing ⚙️
Dirty data → Clean data → Good models
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
# Missing values handle karo
imputer = SimpleImputer(strategy='median')
df[['age', 'income']] = imputer.fit_transform(df[['age', 'income']])
# Categorical variables encode karo
le = LabelEncoder()
df['city'] = le.fit_transform(df['city'])
# Features scale karo
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Train/Validation/Test split
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
print(f"Train: {X_train.shape}, Val: {X_val.shape}, Test: {X_test.shape}")
Stage 5: Model Selection & Training 🧠
"Best model" = Problem ke liye sahi model, na ki most complex.
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
models = {
"Logistic Regression": LogisticRegression(),
"Random Forest": RandomForestClassifier(n_estimators=100),
"Gradient Boosting": GradientBoostingClassifier()
}
# Sabhi models quick comparison karo
for name, model in models.items():
scores = cross_val_score(model, X_train, y_train, cv=5, scoring='f1')
print(f"{name}: {scores.mean():.3f} (+/- {scores.std():.3f})")
# Best model train karo
best_model = RandomForestClassifier(n_estimators=200, random_state=42)
best_model.fit(X_train, y_train)
Stage 6: Model Evaluation 📈
Validation set par evaluate karo — test set sirf end mein!
from sklearn.metrics import (classification_report, confusion_matrix,
roc_auc_score, roc_curve)
# Predictions
y_pred = best_model.predict(X_val)
y_prob = best_model.predict_proba(X_val)[:, 1]
# Detailed report
print(classification_report(y_val, y_pred))
# Confusion matrix
cm = confusion_matrix(y_val, y_pred)
sns.heatmap(cm, annot=True, fmt='d')
plt.title("Confusion Matrix")
plt.show()
# ROC AUC (classification ke liye important)
auc = roc_auc_score(y_val, y_prob)
print(f"ROC AUC: {auc:.3f}")
Evaluation Checklist:
- Business metric achieve hui? (80% accuracy goal)
- Model overfit toh nahi? (Train vs Val performance compare karo)
- Edge cases handle ho rahe hain?
- Bias check kiya? (Sab demographics par equally well perform karta hai?)
Stage 7: Deployment 🚀
# Model save karo
import joblib
joblib.dump(best_model, "churn_model.pkl")
joblib.dump(scaler, "scaler.pkl")
# FastAPI server banao
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
import numpy as np
app = FastAPI(title="Churn Prediction API")
model = joblib.load("churn_model.pkl")
scaler = joblib.load("scaler.pkl")
class UserData(BaseModel):
age: float
monthly_spend: float
tenure_months: int
support_calls: int
@app.post("/predict")
def predict_churn(data: UserData):
features = np.array([[data.age, data.monthly_spend,
data.tenure_months, data.support_calls]])
features_scaled = scaler.transform(features)
prediction = model.predict(features_scaled)[0]
probability = model.predict_proba(features_scaled)[0][1]
return {
"will_churn": bool(prediction),
"churn_probability": float(probability),
"risk_level": "High" if probability > 0.7 else "Medium" if probability > 0.4 else "Low"
}
Stage 8: Monitoring & Improvement 📡
Model deploy karna end nahi hai—shuruwaat hai!
Kya monitor karein:
# Daily performance tracking
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def log_prediction(user_id, features, prediction, actual_outcome=None):
logger.info({
"user_id": user_id,
"prediction": prediction,
"actual": actual_outcome,
"timestamp": datetime.now().isoformat()
})
# Drift detection
if abs(current_avg_probability - baseline_avg) > 0.1:
alert("Data drift detected!")
Improvement Cycle:
- New data collect karo
- Model quarterly retrain karo
- A/B test new model vs old
- Phir deploy!
FAQs
1. Ek AI project kitne time mein complete hota hai? Beginner project: 2-4 weeks. Production-grade: 3-6 months. Depends heavily on data availability.
2. Agar data nahi hai toh kya karein? Public datasets use karo (Kaggle, UCI ML Repository). Web scraping karo (ethically). Synthetic data generate karo.
3. Kaunsa stage sabse zyada time leta hai? Data collection aur preprocessing — 60-80% time yahaan jata hai! Hamesha.
4. Kya har project ke liye yahi workflow follow karna padega? Ye framework hai, rigidly follow karna zaroori nahi. LLM projects mein kuch stages different hoti hain.
5. Portfolio ke liye AI project kahan host karein? GitHub (code), Hugging Face Spaces (demo), Streamlit Community Cloud (free hosting).
Aapka pehla AI project kaunsa tha? Ya banana chahte hain kaunsa? Batao! 🚀