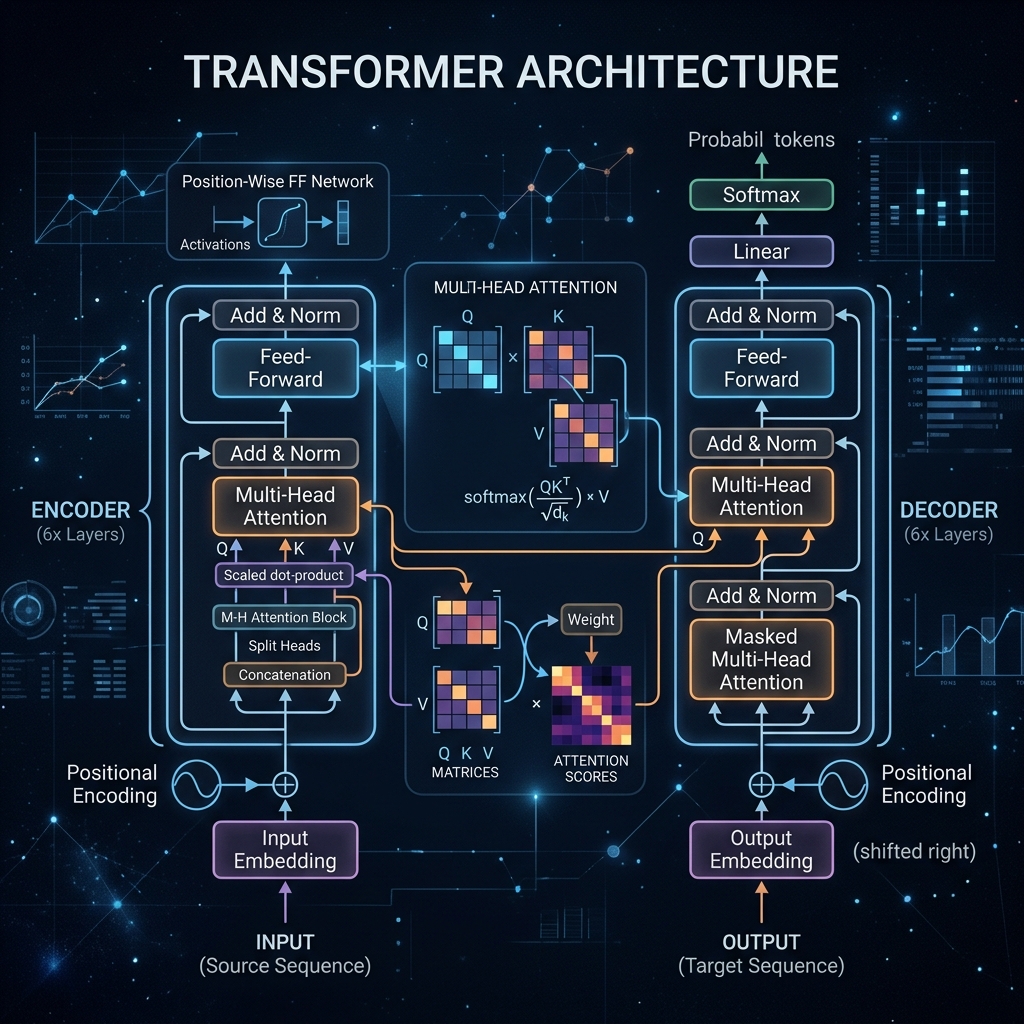
2017 mein Google ke researchers ne ek paper nikala: "Attention Is All You Need". Is ek paper ne poori AI industry ki buniyaad hila di. Aaj ChatGPT, Gemini, Claude, aur BERT — ye sab usi architecture par chalta hai: The Transformer. Ye wo engine hai jisne AI ko insaani bhasha ki gehraai samjhayi hai.
1. Why Transformers? (RNN/LSTM vs Transformers)
RNN aur LSTM mein do badi kamiyan thi:
- Sequential Processing: Wo sentence ko ek-ek word karke padhte the (Slow).
- Short Memory: Lambe sentences mein wo shuruat ke words bhool jate the. Transformers saare words ko "Ek saath" (Parallel) padh sakte hain. Is wajah se inhein train karna 100x fast hai.
2. Self-Attention: The Heart of AI
Self-Attention model ko batata hai ki sentence mein kaunsa word kiske liye hai. Example: "The animal didn't cross the street because it was too tired."
- Yahan model "it" ka rishta "animal" se jode ga, "street" se nahi.
- Iske liye math mein teen vectors use hote hain: Query (Q), Key (K), aur Value (V). Ye bilkul ek YouTube search jaisa hai jahan aap Query daalte hain aur model best Key match karke sahi Result (Value) deta hai.
3. Positional Encoding: Word ka Address
Kyonki Transformer saare words ek saath padhta hai, use ye nahi pata hota ki kaunsa word pehle aaya aur kaunsa baad mein.
- Maan lijiye sentence hai: "Kutte ne billi ko khaya". Agar words shuffle ho gaye toh matlab badal jayega.
- Positional Encoding (Sine/Cosine waves) har word ko ek unique "Address" deta hai taaki order maintain rahe.
4. Multi-Head Attention: Multiple Perspectives
Ek bar dhyan dena kaafi nahi hota. Multi-Head Attention mein model sentence ko alag-alag angles se dekhta hai:
- Head 1: Grammar check karta hai.
- Head 2: Emotional tone samajhta hai.
- Head 3: Pronouns ke rishte nikalta hai. Aakhir mein sabhi heads ka result combine karke ek "Super Understanding" banti hai.
5. Encoder vs Decoder: Understanding vs Generating
- Encoder: Ye input sentence ko samajh kar ek mathematical code mein badalta hai. (BERT isi par base hai).
- Decoder: Ye us code ko dekh kar naya text likhta hai. (GPT models sirf decoder use karte hain).
- Full Transformer: Dono ka milan, jo Google Translate jaise tasks mein use hota hai.
6. Summary Table: Transformer Ecosystem
| Component | What it does? | Why it's magic? |
|---|---|---|
| Self-Attention | Contextual focus | Understands word relationships |
| Multi-Head | Parallel analysis | Sees data from multiple angles |
| Positional Enc | Tracks word order | Preserves meaning of the sentence |
| Feed Forward | Dense processing | Finalizes the learned features |
FAQs
1. "Attention Score" kya hai? Ye ek percentage hai jo batata hai ki word A, word B ke liye kitna important hai. High score matlab model use zyada dhyan (attention) de raha hai.
2. GPT mein 'T' ka kya matlab hai? GPT = Generative Pre-trained Transformer. Ye poora model hi Transformer architecture par based hai.
3. Vision Transformers (ViT) kya hain? Ab Transformers sirf text nahi, balki images ko bhi process kar rahe hain. Ye images ko chote-chote "Patches" mein baant kar scan karte hain.
4. 2026 mein Transformers ka future kya hai? Researchers ab "Linear Transformers" aur "Mamba" jaise naye architectures par kaam kar rahe hain jo Transformers se bhi fast honge, par filhaal Transformer hi King hai.
Transformers AI ki "Soul" hain. Inhein samajh kar hi aap aaj ke advanced LLMs ki working ko decode kar sakte hain! 🤖
Tarun ke baare mein: Tarun attention mechanisms aur large-scale language model architectures ke specialist hain. AI-Gyani par har attention score optimized hai.