Computer ko "A" "B" "C" samajh nahi aata, use sirf 0 aur 1 samajh aata hai. Isliye kisi bhi AI model ko text dene se pehle humein use "Process" aur "Vectorize" karna padta hai. Is post mein hum un techniques ke baare mein baat karenge jo text ko "Machine-Readable" banati hain — Bag of Words se lekar Transformers tak.
1. Safai Abhiyan: Text Preprocessing
Kachre se sona nikalne ki process ko preprocessing kehte hain:
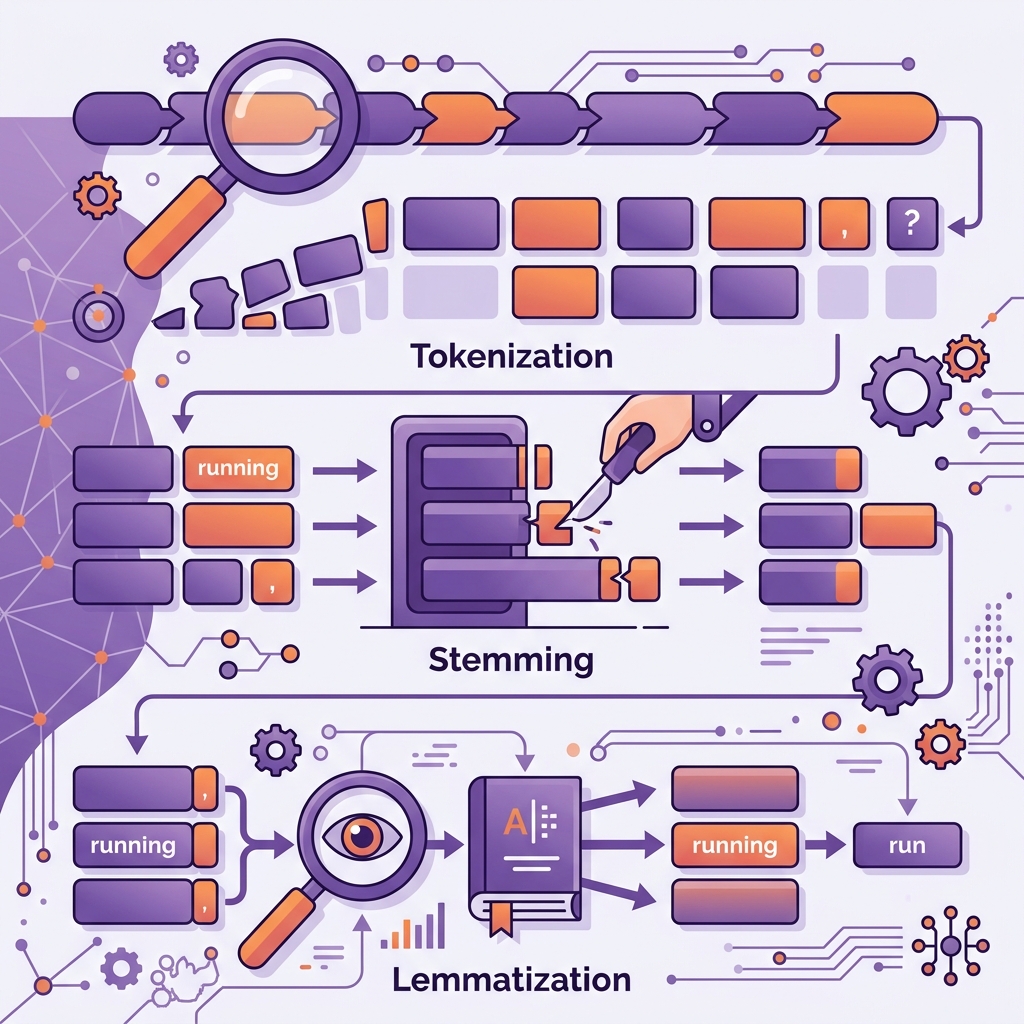
- Tokenization: Sentence ko chhote tukdon (Tokens) mein todna.
- Stopwords Removal: "is", "the", "hai" jaise faltu words hatana jo prediction mein madad nahi karte.
- Stemming vs Lemmatization: Words ko unki root form mein lana. (e.g., "running" -> "run"). Lemmatization zyada smart hai kyonki wo dictionary check karke sahi context nikaalta hai.
2. Bag of Words (BoW): The Counting Game
Ye sabse purana aur simple tareeqa hai.
- Logic: Ye sirf words ki "Count" (Ginti) karta hai.
- Problem: Ismein context bhool jata hai. Model ko nahi pata ki "Not good" aur "Good not" mein kya fark hai.
- Use Case: Simple spam filters ke liye aaj bhi kaafi hai.
3. TF-IDF: Importance ka Math
TF-IDF model ko batata hai ki kaunsa word "Unique" hai.
- TF (Term Frequency): Ek word paragraph mein kitni baar aaya.
- IDF (Inverse Document Frequency): Wo word poore internet par kitna rare hai.
- Example: Agar "AI" word har document mein hai, toh ye use kam importance dega. Par agar "Quantum" sirf ek mein hai, toh ye use high score dega. Ise hum Keyword Extraction mein use karte hain.
4. N-Grams: Context ka chhota tukda
Kayi baar single word ka matlab nahi nikalta.
- Unigram: "Not"
- Bigram: "Not good" (Meaning badal gaya!)
- Trigram: "Not very good" N-Grams model ko padosi words (neighbors) ka context samajhne mein madad karte hain.
5. Word Embeddings: The AI Soul
Ye sabse advanced technique hai jahan words "Vectors" ban jate hain.
- Logic: Words ko 300-1536 dimensions mein store karna.
- King - Man + Woman = Queen: Ye math embeddings mein possible hai!
- Word2Vec aur GloVe: Ye models words ke aapsi rishton (Semantics) ko samajhte hain.
6. Summary Table: NLP Toolkit Comparison
| Technique | Goal | Best For |
|---|---|---|
| Tokenization | Breaking text | Initial step |
| Stopwords | Cleaning noise | Search engines |
| TF-IDF | Feature extraction | Document similarity |
| Word Embeddings | Contextual meaning | Chatbots / LLMs |
FAQs
1. BoW aur TF-IDF mein kaun behtar hai? Zyadatar TF-IDF behtar hai kyonki wo common words ka "Noise" filter kar deta hai aur important features ko highlight karta hai.
2. Word Embeddings train kaise hoti hain? Ye Neural Networks se train hoti hain jahan model internet ke arbon sentences padh kar seekhta hai ki "Doctor" aur "Hospital" hamesha saath kyun aate hain.
3. "NER" (Named Entity Recognition) kya hai? Ye ek technique hai jo text mein se "Insaan ka naam", "Location", aur "Date" ko automatically pehchan kar extract karti hai.
4. 2026 mein kaunsi technique top par hai? Ab hum Attention Mechanism use kar rahe hain (Transformers), jo sentence ke har word ka rishta doosre har word se nikaalta hai.
NLP techniques text ka "X-ray" hain. Inke bina AI bhasha ko kabhi nahi samajh sakta! 🔍
Tarun ke baare mein: Tarun mathematical linguistics aur semantic data parsing ke specialist hain. AI-Gyani par har technique logic-driven aur efficient hai.