Bahut log Machine Learning theory jaante hain — Supervised Learning, Neural Networks, Gradient Descent. Par jab bolte hain "Ek complete ML project banao", tab pata chalta hai ki steps ka order nahi pata.
Ek professional Data Scientist ke liye ML Workflow — data se deployment tak ka process — bilkul roadmap ki tarah hota hai. Iske bina aap sirf algorithms ki theory padhte rahoge, real kaam nahi karoge.
Is post mein hum ek real house price prediction project ke through poora workflow Python code ke saath dekhenge.
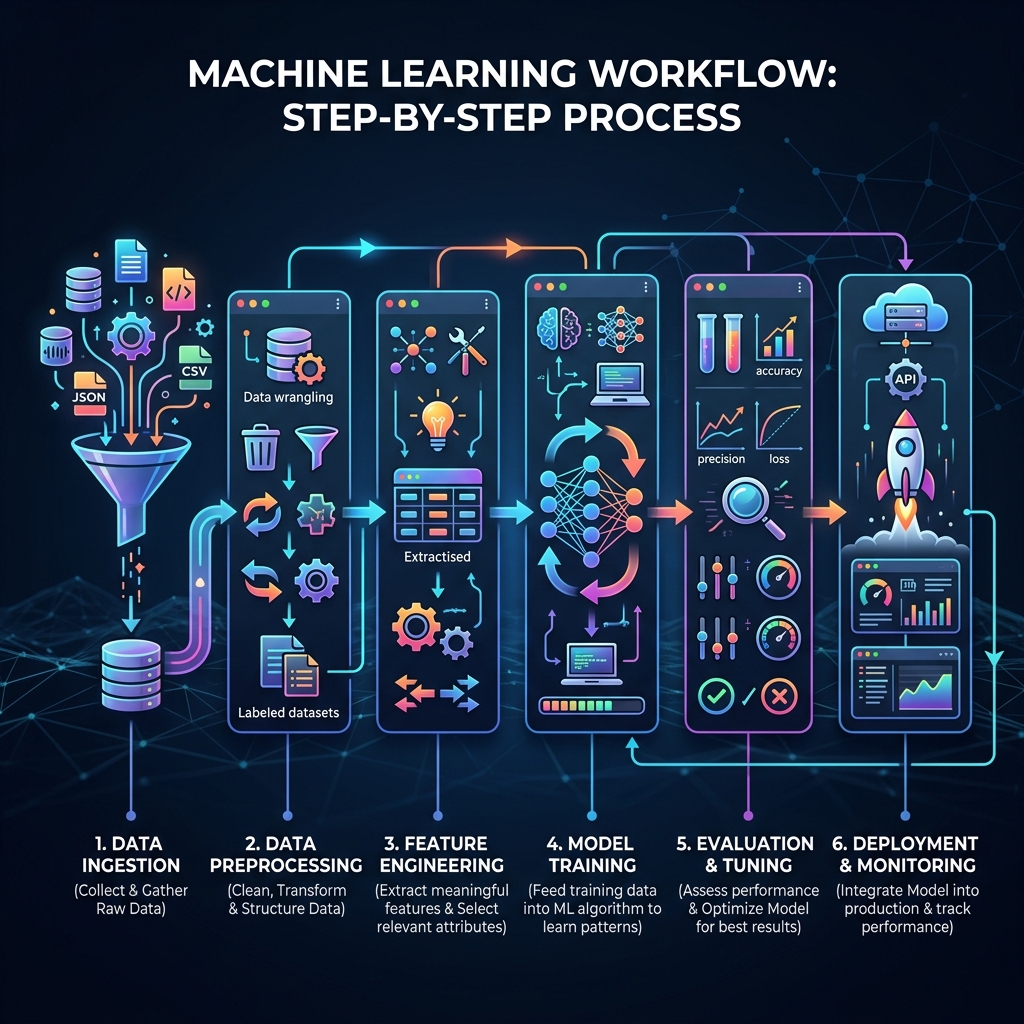
ML Workflow — 7 Steps Overview
1. Problem Definition
↓
2. Data Collection
↓
3. Data Preprocessing
↓
4. EDA (Exploratory Data Analysis)
↓
5. Feature Engineering & Selection
↓
6. Model Training & Evaluation
↓
7. Deployment & Monitoring
Step 1: Problem Definition — Samasya Ko Samajhna
Sabse pehle ye socho: Hum kya predict karna chahte hain?
# Problem clearly define karo:
# INPUT → Ghar ka size, bedrooms, location, age
# OUTPUT → Price (₹ mein)
# TYPE → Regression (continuous number predict karna)
# SUCCESS METRIC → R² score > 0.85, MAE < ₹5 lakh
# Wrong approach: seedha model train karna
# Right approach: problem samajhna pehle
| Question | Answer |
|---|---|
| Kya predict karein? | House price |
| ML type kaunsa? | Supervised Regression |
| Success kaise measure? | R² score, Mean Absolute Error |
| Baseline kya hai? | Simple average price |
Step 2: Data Collection — Quality Data Laana
import pandas as pd
import numpy as np
# Option 1: Kaggle se dataset
# kaggle datasets download -d harlfoxem/housesalesprediction
# Option 2: Synthetic data (practice ke liye)
np.random.seed(42)
n = 1000
data = {
'size_sqft': np.random.randint(500, 3000, n),
'bedrooms': np.random.randint(1, 6, n),
'bathrooms': np.random.randint(1, 4, n),
'age_years': np.random.randint(0, 50, n),
'location_score': np.random.uniform(1, 10, n),
'has_parking': np.random.choice([0, 1], n),
}
# Price formula (realistic)
data['price_lakh'] = (
data['size_sqft'] * 0.05 +
data['bedrooms'] * 5 +
data['location_score'] * 8 -
data['age_years'] * 0.5 +
data['has_parking'] * 10 +
np.random.normal(0, 8, n) # Noise add karo
)
df = pd.DataFrame(data)
print(f"Dataset shape: {df.shape}")
print(df.head())
Data quality check:
print(df.info()) # Data types aur null values
print(df.describe()) # Statistics
print(df.isnull().sum()) # Missing values count
Step 3: Data Preprocessing — Saaf Karna
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
# Missing values handle karo
imputer = SimpleImputer(strategy='median')
df[['size_sqft', 'age_years']] = imputer.fit_transform(
df[['size_sqft', 'age_years']]
)
# Outliers remove karo (IQR method)
def remove_outliers(df, column):
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
return df[(df[column] >= lower) & (df[column] <= upper)]
df = remove_outliers(df, 'price_lakh')
print(f"After outlier removal: {len(df)} rows")
Step 4: EDA — Data Ko Samajhna
import matplotlib.pyplot as plt
import seaborn as sns
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# Price distribution
axes[0,0].hist(df['price_lakh'], bins=30, color='steelblue', edgecolor='white')
axes[0,0].set_title('Price Distribution')
axes[0,0].set_xlabel('Price (Lakh ₹)')
# Size vs Price
axes[0,1].scatter(df['size_sqft'], df['price_lakh'], alpha=0.4, color='coral')
axes[0,1].set_title('Size vs Price')
axes[0,1].set_xlabel('Size (sqft)')
axes[0,1].set_ylabel('Price (Lakh ₹)')
# Correlation heatmap
corr = df.corr()
sns.heatmap(corr, annot=True, fmt='.2f', cmap='coolwarm', ax=axes[1,0])
axes[1,0].set_title('Feature Correlation')
# Bedrooms vs Price (boxplot)
df.boxplot(column='price_lakh', by='bedrooms', ax=axes[1,1])
axes[1,1].set_title('Price by Bedrooms')
plt.tight_layout()
plt.savefig('eda_plots.png', dpi=120, bbox_inches='tight')
plt.show()
# Key insight:
print("Correlation with price:")
print(df.corr()['price_lakh'].sort_values(ascending=False))
Step 5: Feature Engineering & Selection
# Naye useful features banao
df['price_per_sqft'] = df['price_lakh'] / df['size_sqft'] * 100
df['rooms_total'] = df['bedrooms'] + df['bathrooms']
df['age_category'] = pd.cut(df['age_years'],
bins=[0, 5, 15, 30, 100],
labels=['New', 'Recent', 'Old', 'Very Old'])
# One-hot encoding
df = pd.get_dummies(df, columns=['age_category'], drop_first=True)
# Feature importance (quick check)
from sklearn.ensemble import RandomForestRegressor
X_temp = df.drop('price_lakh', axis=1)
y_temp = df['price_lakh']
rf_temp = RandomForestRegressor(n_estimators=50, random_state=42)
rf_temp.fit(X_temp, y_temp)
importance = pd.Series(rf_temp.feature_importances_, index=X_temp.columns)
print("Top features:")
print(importance.sort_values(ascending=False).head(6))
Step 6: Model Training & Evaluation
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.metrics import r2_score, mean_absolute_error
import warnings
warnings.filterwarnings('ignore')
# Features aur target prepare karo
feature_cols = ['size_sqft', 'bedrooms', 'bathrooms', 'age_years',
'location_score', 'has_parking', 'rooms_total']
X = df[feature_cols]
y = df['price_lakh']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale karo
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Multiple models compare karo
models = {
'Linear Regression': LinearRegression(),
'Ridge Regression': Ridge(alpha=1.0),
'Random Forest': RandomForestRegressor(n_estimators=100, random_state=42),
'Gradient Boosting': GradientBoostingRegressor(n_estimators=100, random_state=42),
}
results = {}
for name, model in models.items():
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
r2 = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
cv_scores = cross_val_score(model, X_train_scaled, y_train, cv=5, scoring='r2')
results[name] = {'R²': round(r2, 3), 'MAE (Lakh)': round(mae, 2), 'CV Mean R²': round(cv_scores.mean(), 3)}
print(f"{name}: R²={r2:.3f}, MAE=₹{mae:.2f}L, CV={cv_scores.mean():.3f}")
Best model select karo:
# Random Forest typically best results deta hai
best_model = RandomForestRegressor(n_estimators=200, max_depth=10, random_state=42)
best_model.fit(X_train_scaled, y_train)
# Test karo
test_house = [[1500, 3, 2, 8, 7.5, 1, 5]]
test_scaled = scaler.transform(test_house)
predicted = best_model.predict(test_scaled)
print(f"Predicted price: ₹{predicted[0]:.1f} Lakh")
Step 7: Deployment — Real World Mein Laana
import joblib
# Model save karo
joblib.dump(best_model, 'house_price_model.pkl')
joblib.dump(scaler, 'feature_scaler.pkl')
# FastAPI se serve karo
# pip install fastapi uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class HouseFeatures(BaseModel):
size_sqft: float
bedrooms: int
bathrooms: int
age_years: int
location_score: float
has_parking: int
rooms_total: int
@app.post("/predict")
def predict_price(features: HouseFeatures):
model = joblib.load('house_price_model.pkl')
scaler = joblib.load('feature_scaler.pkl')
data = [[features.size_sqft, features.bedrooms, features.bathrooms,
features.age_years, features.location_score,
features.has_parking, features.rooms_total]]
scaled = scaler.transform(data)
price = model.predict(scaled)[0]
return {"predicted_price_lakh": round(price, 2)}
# uvicorn main:app --reload se run karo
Common Mistakes Jo Beginners Karte Hain
| Mistake | Problem | Solution |
|---|---|---|
| Test data pehle dekhna | Data leakage | Strict train/test split |
| Scaling bhool jaana | Model confused | StandardScaler hamesha |
| Sirf ek model try karna | Sub-optimal | Multiple compare karo |
| CV nahi karna | Unreliable results | cross_val_score use karo |
| EDA skip karna | Blind model building | Hamesha visualize karo |
FAQs
1. Kitna time lagta hai ek complete ML project mein? Toy project (clean data): 2-4 hours. Real-world project: 2-4 weeks (data cleaning hi 60% time leta hai).
2. Kya deployment zaroori hai portfolio ke liye? Haan! "I built a model" se zyada impact hai "I deployed a model users can try." Streamlit ya HuggingFace Spaces par free deploy karo.
3. EDA skip karein toh kya hoga? Model train ho jaayega, par aap nahi samjhoge ki wo galat predictions kyun de raha hai. Debugging bahut mushkil hogi.
4. Cross-validation hamesha zaroori hai? Small datasets (< 10,000 rows) ke liye haan. Bade datasets par simple train-test split bhi kaam karta hai.
5. Ek project mein kitne algorithms try karein? Minimum 3-4. Ek baseline (Linear Regression), ek tree-based (Random Forest), ek boosting (XGBoost). Compare karo phir best choose karo.
ML Workflow clear hua? Ab real dataset uthao aur practice karo! 🚀
Tarun ke baare mein: Tarun ek AI educator hain jo ML workflow ko practical Python projects ke through sikhate hain. AI-Gyani par har step real code ke saath milta hai.