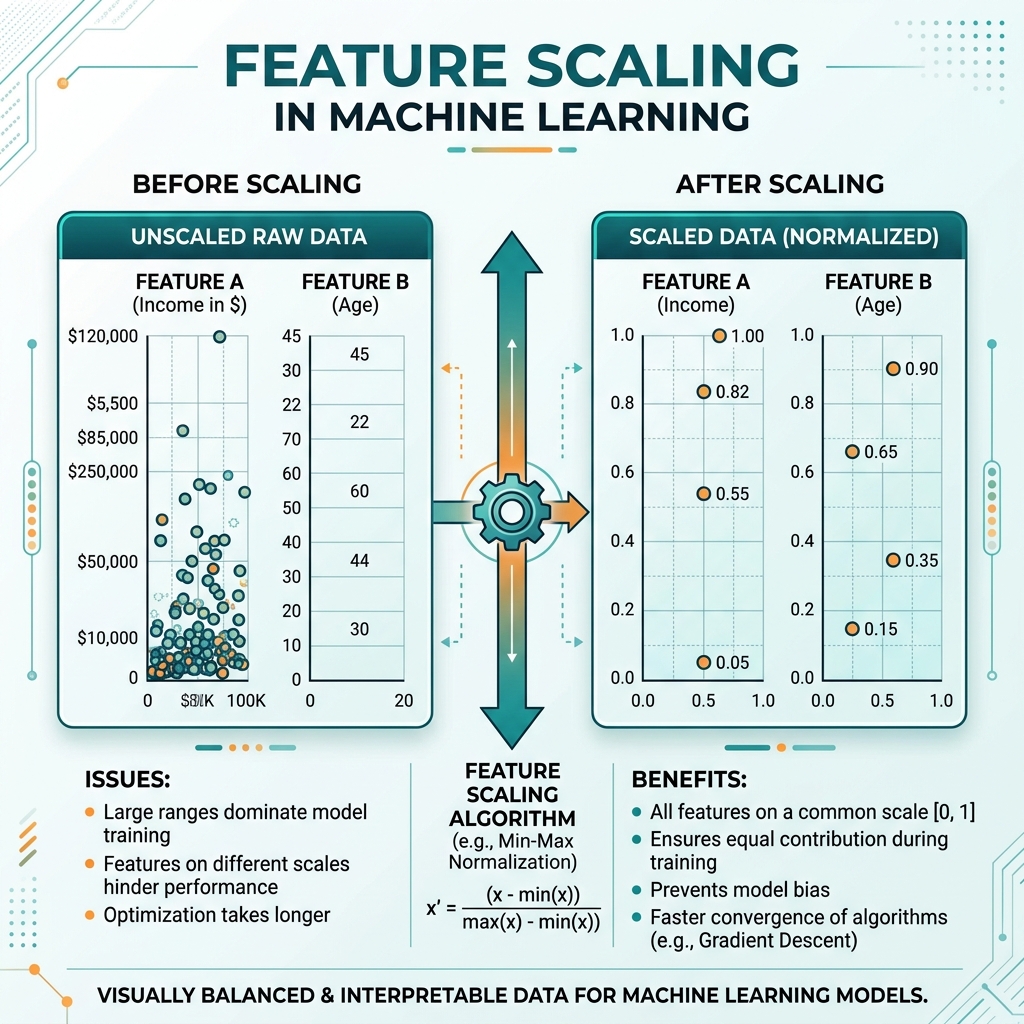
Socho aap ek AI model bana rahe hain jo "Health Score" predict kare. Features hain:
- Body Temperature: 97 to 105 (Chhota range)
- Steps Walked: 0 to 20,000 (Bahut bada range)
AI model sochega, "Arre, Steps toh 20,000 hain aur Temperature sirf 98, iska matlab Steps zyada important hain!" Galti! 1 degree temperature badhna 1000 steps se zyada important ho sakta hai. In numbers ko ek barabar level (scale) par laana hi Feature Scaling hai.
1. Do Main Tareeqe: Normalization vs Standardization
A. Min-Max Normalization (0 se 1 ke beech)
Ye har value ko nichodh (squeeze) kar 0 aur 1 ke beech le aata hai.
- Kab use karein: Jab aapko pata ho ki data ki limits kya hain (jaise pixels 0-255).
- Nuqsan: Agar ek outlier aa gaya (jaise 1,00,000 steps), toh baaki saara data 0 ke bahut kareeb dikhne lagega.
B. Standardization (Z-Score Scaling)
Ye data ka Mean 0 aur Std Dev 1 kar deta hai. Iska koi fixed range nahi hota (values -3 se +3 ke beech ho sakti hain).
- Kab use karein: Jab data mein outliers hon. Ye unse darta nahi hai.
2. Kab Scaling Zaroori hai?
Saare AI algorithms ko scaling nahi chahiye hoti.
-
Scaling Zaroori hai:
- Distance-based: KNN, SVM, K-Means. Inmein math "Do points ke beech ki doori" nikaalti hai. Agar ek coordinate 1000 hai aur doosra 1, toh math fail ho jayegi.
- Gradient Descent based: Logistic Regression, Neural Networks. Scaling se "Pahaad se utarna" fast ho jata hai.
-
Scaling Zaroori NAHI hai:
- Tree-based: Decision Trees, Random Forest, XGBoost. Inmein math "Splitting" (Partition) karti hai, isliye scale se farq nahi padta.
3. Data Leakage: Sabse Badi Galti
Ek professional developer hamesha scaling training data par karta hai aur wahi scale test data par apply karta hai. Agar aapne poore dataset par ek saath scaling kar di, toh test data ki jaankari training mein "leak" ho jayegi, aur aapki accuracy fake (galat) dikhegi.
4. Comparison Table: Kaunsa Scaler kab?
| Scaler | Range | Outliers? | Recommendation |
|---|---|---|---|
| Min-Max | 0 to 1 | Sensitive | Images, Neural Nets |
| Standard | Mean=0, SD=1 | Robust | ML Algorithms, PCA |
| Robust Scaler | Median based | Best | Jab bahut zyada outliers hon |
FAQs
1. Kya scaling se accuracy badhti hai? KNN aur SVM jaise models mein accuracy 20-30% tak badh sakti hai. Decision Trees mein koi farq nahi padta.
2. Kya mujhe har column ko scale karna chahiye? Haan, saare numerical columns ko scale karna best practice hai. Categorical (text) columns ko pehle Encoding karke phir check kiya jata hai.
3. Scaling pehle karein ya Train-Test Split?
Hamesha Train-Test Split pehle karein. Uske baad sirf Train data par Scaler ko fit karein aur Test data ko sirf transform karein.
4. Normalization aur Scaling mein kya fark hai? Scaling ek broader term hai. Normalization uske andar ka ek tareeqa hai jo data ko 0-1 range mein lata hai.
Sahi scaling aapke model ko "Andha" hone se bachati hai. Ise skip karna matlab galti ko invitation dena! 📏
Tarun ke baare mein: Tarun ko messy data ko clean aur professional formats mein badalna pasand hai. AI-Gyani par har feature scaled aur balanced hai.