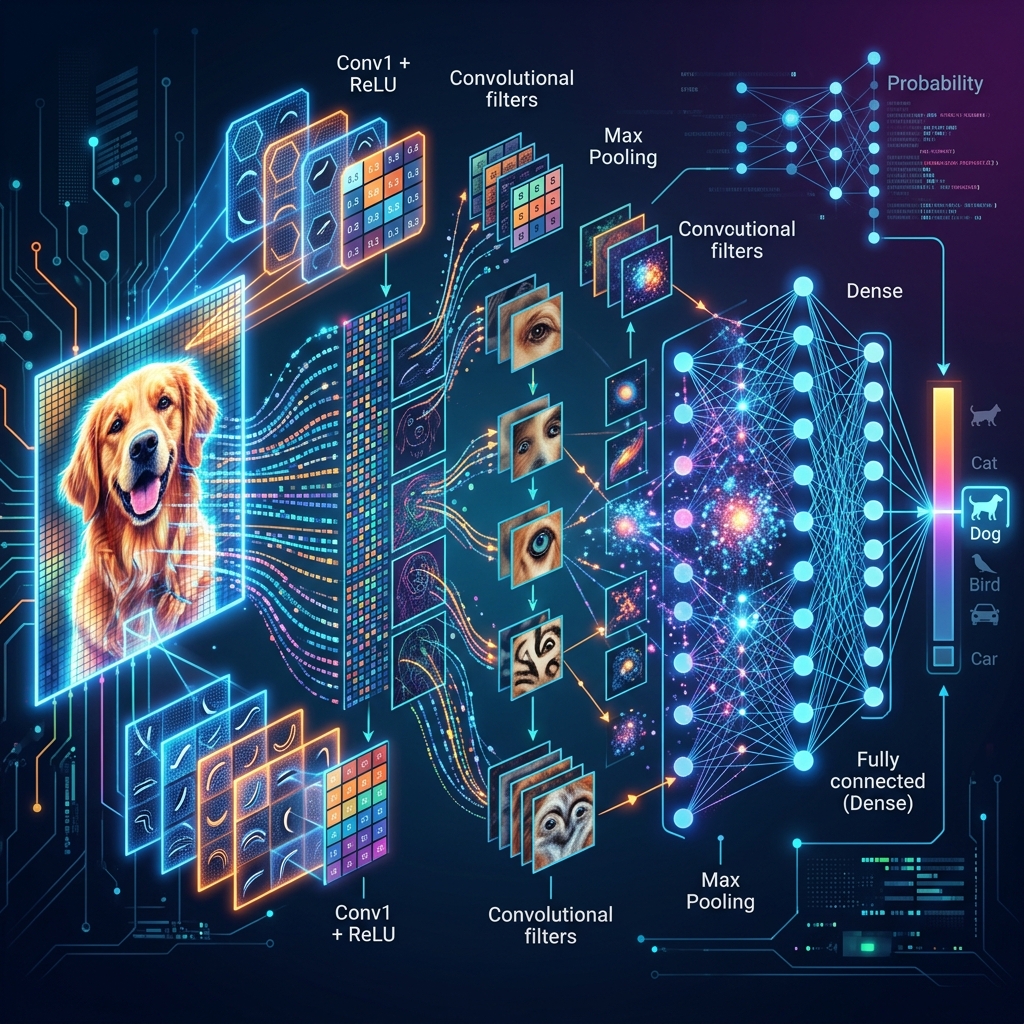
Ek normal Neural Network (ANN) ko agar hum 1000x1000 ki image dein, toh use 10 lakh inputs process karne padenge. Ye computer ko hang kar dega. Isliye hum CNN (Convolutional Neural Networks) use karte hain. Ye poori image ko ek saath nahi, balki tukdon mein "Soot-ta" (Scan) hai, bilkul waise hi jaise insaani aankh scan karti hai.
1. Convolution: The Pattern Finder
CNN ka pehla step hai Convolution.
- Filters/Kernels: Ye chote matrices hote hain (e.g., 3x3) jo image ke upar slide karte hain.
- Ek filter sirf "Vertical Lines" dhoondhta hai, dusra "Horizontal Lines", aur teesra "Corners".
- Stride: Filter kitne pixels jump karega. Stride 1 matlab detailed scan, Stride 2 matlab fast scan.
2. Pooling: Reducing the Burden
Convolution ke baad humein bahut saara data milta hai. Pooling use chhota karti hai.
- Max Pooling: 2x2 ki grid mein se sabse badi value uthana. Isse model "Position Independent" ban jata hai — chahe billi photo ke upar ho ya niche, model use pehchan lega.
- Padding: Agar hum chahte hain ki image ka size chota na ho, toh hum "Zeros" ki ek diwaar bana dete hain image ke charon taraf.
3. The Architecture Flow
Ek professional CNN model aise dikhta hai:
Input Image -> [Convolution -> ReLU -> Pooling] x N -> Flatten -> Fully Connected Layer -> Softmax (Output)
- Pehli layers basic patterns dhoondhti hain.
- Gehari (Deep) layers complex cheezein pehchanti hain jaise chehra ya gaadi ka pahiya.
4. Popular Pre-trained Models
2026 mein koi zero se model nahi banata. Hum Transfer Learning use karte hain:
- VGG-16: Simple aur deep.
- ResNet-50: Ismein "Skip Connections" hote hain jo bahut deep networks (100+ layers) ko train karna asaan banate hain.
5. Summary Table: CNN Operations
| Operation | What it does? | Benefit |
|---|---|---|
| Convolution | Multiplies Filter with Image | Extracts local features |
| ReLU | Negative values to Zero | Adds non-linearity |
| Max Pool | Picks maximum pixel | Reduces data size |
| Softmax | Probabilities for classes | Final classification |
FAQs
1. "Kernel Size" 3x3 hi kyon hota hai? 3x3 aur 5x5 sabse popular hain kyonki ye "Center Pixel" aur uske padosiyon ke beech ka rishta acche se samajh paate hain.
2. "Dropout" layer kyon add karte hain? Ye model ko "Overfitting" se bachati hai. Ye training ke waqt randomly kuch neurons ko "Shut down" kar deti hai taaki model kisi ek feature par zaroorat se zyada bharosa na kare.
3. Kya CNN video par kaam karta hai? Haan, video sirf "Sequence of images" hi toh hai. CNN har frame ko scan karta hai aur RNN use "Yaad" rakhta hai.
4. CNN aur OpenCV mein kya fark hai? OpenCV manual filters use karta hai. CNN khud seekhta hai ki kaunsa filter best hai (Automated Feature Learning).
CNN ne computer ko "Aankhein" di hain. Ise samajh kar aap Face Recognition se lekar Medical Imaging tak sab kuch build kar sakte hain! 👁️
Tarun ke baare mein: Tarun visual recognition architectures aur feature map optimization ke specialist hain. AI-Gyani par har convolution clear hai.